Dynamic Yield uses a score called Probability to be Best to determine how to allocate variations across your site's traffic. The score is based on a Bayesian statistical approach.
This article describes why Dynamic Yield uses the Bayesian approach and gets into some of the heavy math behind how it works.
Frequentist vs. Bayesian
In the field of statistical inference, there are two very different yet mainstream schools of thought: the frequentist approach and the Bayesian approach.
The difference between these two rival schools can be explained through the different interpretations each gives to the term probability. The intro given here is adapted from this series of blog posts.
Take a concrete case-in-point: Say you want to find out the average height of US citizens. For a frequentist, this number is unknown but fixed. This is a natural intuitive view, as you can imagine that if you go through all US citizens one by one, measure their height, and then find the average of those measurements, you'll get the actual number.
However, because you don't have access to all US citizens, you take a sample instead, of say, 1,000 citizens. You measure and average their height to produce a point estimate and then calculate your error estimate. The point is that either way, the frequentist looks at the average height as a single unknown number.
A Bayesian statistician, however, would view the situation very differently. A Bayesian would look at the average height of a US citizen not as a fixed number but rather as an unknown distribution (you might imagine here a “bell” shaped normal distribution).
The Bayesian engine provides answers to questions such as:
What is the probability that A is better than B? (contrast this with the contrived p-value (measure of probability) from the previous method).
If I declare B the winner, and it isn't really better, how much should I expect to lose in terms of conversion rate?
Here's a summary of how the two frameworks compare:
| Hypothesis Testing | Bayesian A/B Testing | |
|---|---|---|
| Knowledge of baseline performance | Required | Not required |
| Intuitiveness | Less intuitive, as p-value is a convoluted term | More intuitive, as we directly calculate the probability of A being better than B |
| Sample size | Predefined | No need to predefine |
| Peeking at the data while the test runs | Not allowed | Allowed (with caution) |
| Quick to make decisions | Less, as it has more restrictive assumptions on distributions | More, as it has less restrictive assumptions |
| Representing uncertainty | Confidence interval: An interpretation that's often misunderstood | Highest posterior density region: A highly intuitive interpretation |
| Declaring a winner | When the sample size is reached and the p-value is below a certain threshold | Either when the probability to be best score rises above a threshold, or the expected loss falls below a threshold (in which case a “tie” can be declared between multiple variations) |
Note that generally speaking, a frequentist A/B testing framework that performs as well as the Bayesian framework described here is possible, but further development would be needed beyond what's usually implemented.
Bayesian statistics and probability: How it breaks down
Initially, the Bayesian statistician assumes some basic prior knowledge: For example, that the average height is somewhere between 50 cm and 250 cm.
Then, the Bayesian begins to measure heights of specific US citizens, and with each measurement updates the distribution to become a bit more bell-shaped around the average height measured so far. As more data is collected, the bell becomes sharper and more concentrated around the measured average height.
For Bayesians, probabilities are fundamentally related to what they know about an event. This means, for example, that in a Bayesian view, it's possible to meaningfully talk about the probability that the true conversion rate lies within a given range, and that probability codifies the knowledge of the value based on prior information and available data.
The Bayesian concept of probability is extended to cover degrees of certainty about any given statement about reality. However, in a strict frequentist view, it's meaningless to discuss the probability of the true conversion rate. For frequentists, the true conversion rate is by definition a single fixed number, and a probability distribution for a fixed number is mathematically nonsensical.
The same logic applies to measuring the conversion rate of a web-based purchase funnel. Sure, probability can certainly be estimated in a frequentist fashion by measuring the ratio of how many times a conversion was made out of a huge number of trials. But this is not necessary for the Bayesian, who can stop the test at any point and calculate probabilities from data.
To illustrate the convergence process of the distribution as more data is collected, here is a plot based on test data. Note how the bell shape becomes sharper (more certain) as data streams in:
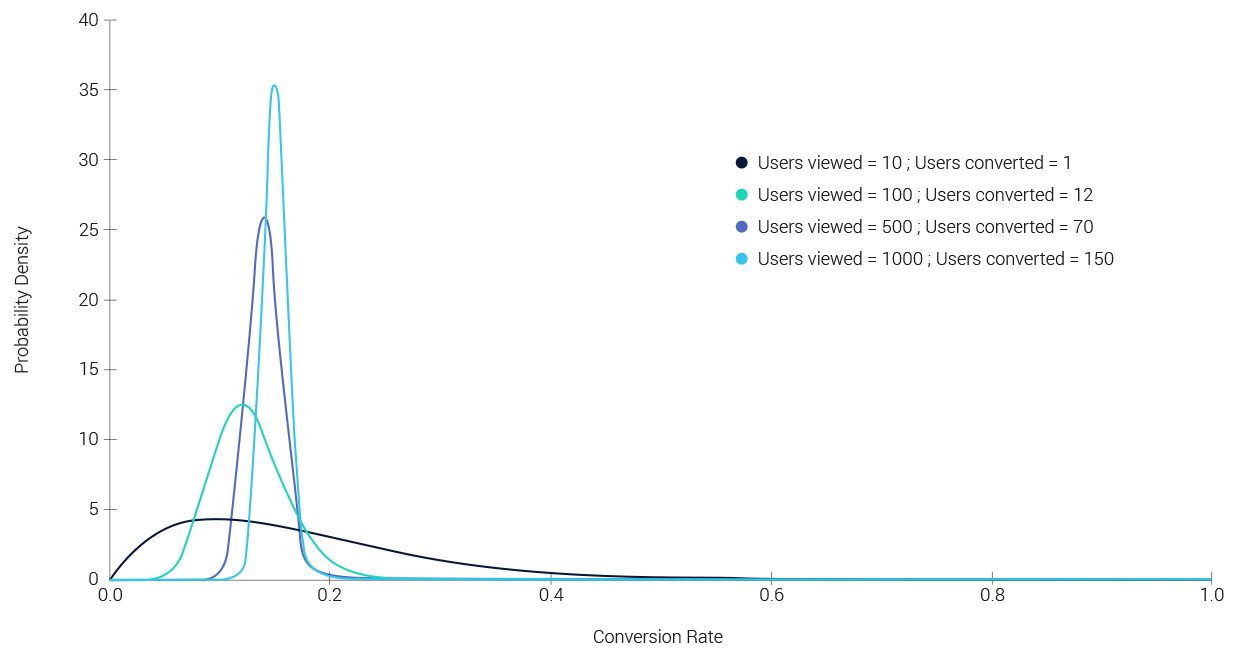
The surprising thing is that this arguably subtle difference in philosophy between these schools leads in practice to vastly different approaches to the statistical analysis of data.
Declaring a winner
When the posterior distributions are mapped for the variations, a winner is decided by sampling a large number of observations. Say, hypothetically, that you take a sample of 1000 results from 2 variations, looking like this:
You see that 999 times out of the 1000 samples the orange variation has a higher probability. So the probability that the orange variation is better than blue one is: (999/1000) * 100, or 99.9%. Dynamic Yield engines samples 300,000 results from every variation to calculate the probability to be best.
The mathematics behind the Bayesian model
In Bayesian the real mean is a distribution, but the observations are fixed, which models real-life behavior much better. To be more precise, taking the case of a Bernoulli distribution, the probability mass function (pmf) is defined as:
π being the probability of clicking. Here, according to the Bayesian approach, Pi should also have a distribution of its own, its own parameters, and so on.
To calculate the mean click-through rate, similar to the maximum likelihood mean value in a traditional A/B test, we try to solve for the value in the below equation:
Where X = the observed data
We apply the Bayesian conditional probability equation:
Here, p(X) can be treated as a normalizing constant, given its independence from π.
Therefore:
- p(π)= probability of click before the experiment began – the prior
- p(X|π)= the observed data samples – the likelihood
- p(π|X) = the probability of click after observing the sample – the posterior
Prior, likelihood, and posterior probability distributions
Prior probability is the probability to click on a variation before any sample data is collected, likelihood is the probability distribution of the collected sample data, and posterior probability is the probability to click a variation after the taking the sampled data observations into account.
In Bayesian probability theory, if the posterior distribution has the same probability distribution as the prior probability distribution given a likelihood function, then the prior and posterior are called conjugate distributions and the prior is called a conjugate prior for the likelihood function.
For example, in our case: If the likelihood function is Bernoulli distributed, choosing a beta prior over the mean will ensure that the posterior distribution is also beta distributed. So in essence the beta distribution is a conjugate prior for the likelihood that is Bernoulli distributed!
As we are dealing with a Bernoulli distribution, we only have to deal with one random variable (). So assuming our likelihood function follows a prior-beta distribution:
Assuming the experiment begins with no prejudice, a beta distribution for the prior with α=1; β=1would be a good starting point as beta(1,1) is a uniform distribution.
Grouping the similar terms together:
We can see that the posterior is simply a beta distribution of the form:
Where:
which is exactly the same as our prior probability distribution, which was:
Thus, confirming the conjugate priors concept for binary outcomes.
Therefore to solve for a posterior probability for binary outcomes the blueprint would be:
Blueprint:
- Beta(1,1): assume the prior distribution is uniform
- Sample x1
- Beta(1+x1 ,1+1- x1): Update the beta distribution to account for the sample observed data
- Sample x2
- Beta(1+x2 ,1+2- x2)
- Repeat from step 2
In the end we reach a beta distribution that progresses from a uniform distribution to a skinny normal distribution.
Sample implementation in Python
This following script illustrates how the Bayesian probability changes over time as the number of samples increases:
from __future__ import print_function, division
#! usr/bin/env python"
__author__ = "SivaGabbi"
__copyright__ = "Copyright 2019, Dynamic Yield"
from builtins import rangev
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import beta
NUM_TRIALS = 2000
CLICK_PROBABILITIES = [0.35,0.75]
class Variation(object):
def __init__(self, p):
self.p = p
self.a = 1
self.b = 1
def showVariation(self):
return np.random.random() maxsample:
maxsample = sample
bestv = v
if i in sample_points:
print("current samples: %s" % allsamples)
plot(variations, i)
# show the variation with the largest sample
x = bestv.showVariation()
# update the distribution for the variation which was just sampled
bestv.updateVariation(x)
if __name__ == "__main__":
experiment()